|
|
@@ -59,7 +59,9 @@
|
|
|
|
|
|
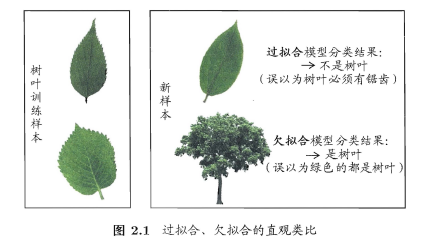
可以得知:在过拟合问题中,训练误差十分小,但测试误差教大;在欠拟合问题中,训练误差和测试误差都比较大。目前,欠拟合问题比较容易克服,例如增加迭代次数等,但过拟合问题还没有十分好的解决方案,过拟合是机器学习面临的关键障碍。
|
|
|
|
|
|
-
|
|
|
+```
|
|
|
+
|
|
|
+```
|
|
|
|
|
|
**2.2 评估方法**
|
|
|
|
|
|
@@ -81,7 +83,9 @@
|
|
|
|
|
|
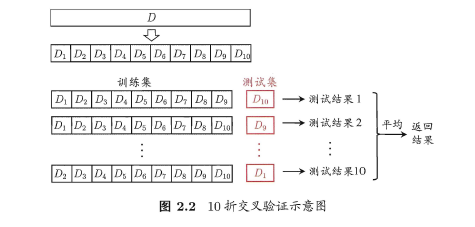
将数据集D划分为k个大小相同的互斥子集,满足D=D1∪D2∪...∪Dk,Di∩Dj=∅(i≠j),同样地尽可能保持数据分布的一致性,即采用分层抽样的方法获得这些子集。交叉验证法的思想是:每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集,这样就有K种训练集/测试集划分的情况,从而可进行k次训练和测试,最终返回k次测试结果的均值。交叉验证法也称“k折交叉验证”,k最常用的取值是10,下图给出了10折交叉验证的示意图。
|
|
|
|
|
|
-
|
|
|
+```
|
|
|
+
|
|
|
+```
|
|
|
|
|
|
与留出法类似,将数据集D划分为K个子集的过程具有随机性,因此K折交叉验证通常也要重复p次,称为p次k折交叉验证,常见的是10次10折交叉验证,即进行了100次训练/测试。特殊地当划分的k个子集的每个子集中只有一个样本时,称为“留一法”,显然,留一法的评估结果比较准确,但对计算机的消耗也是巨大的。
|
|
|
|
|
|
@@ -91,8 +95,10 @@
|
|
|
|
|
|
自助法的基本思想是:给定包含m个样本的数据集D,每次随机从D 中挑选一个样本,将其拷贝放入D',然后再将该样本放回初始数据集D 中,使得该样本在下次采样时仍有可能被采到。重复执行m 次,就可以得到了包含m个样本的数据集D'。可以得知在m次采样中,样本始终不被采到的概率取极限为:
|
|
|
|
|
|
-
|
|
|
-
|
|
|
+```
|
|
|
+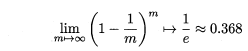
|
|
|
+```
|
|
|
+
|
|
|
这样,通过自助采样,初始样本集D中大约有36.8%的样本没有出现在D'中,于是可以将D'作为训练集,D-D'作为测试集。自助法在数据集较小,难以有效划分训练集/测试集时很有用,但由于自助法产生的数据集(随机抽样)改变了初始数据集的分布,因此引入了估计偏差。在初始数据集足够时,留出法和交叉验证法更加常用。
|
|
|
|
|
|
**2.4 调参**
|

 Wei Ao
Wei Ao